In 2018, there have been a bunch of open source projects from various companies and communities that offer alternative container runtimes that claim to offer better container isolation. Most of them plug in to the standard container / Kubernetes ecosystem through the Open Container Initiative (OCI) standard.
In this blog post, we will take a brief look at the following container runtimes to see how their approach to isolation differs:
runc (libcontainer)
runc is the container runtime that powers Docker (as well as a large portion of the current container ecosystem). It is currently being developed under the umbrella of the Open Container Initiative (OCI).
With runc, a container is essentially a Linux userland process that has been isolated through a combination of kernel features: namespaces, cgroups and capabilities.
In addition, SELinux and/or AppArmor profiles can be applied to further restrict what the container can access. Docker by default uses a fairly permissive AppArmor profile that provides maximum application compatibility.
With runc, you end up with a system that looks something like this:
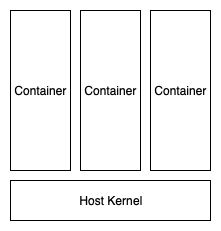
The main problem with container isolation in this configuration is that the containers share a kernel. A vulnerability in the Linux kernel that allows an attacker to overwrite certain kernel structures will break the isolation between containers. Essentially, any privilege escalation vulnerability in the Linux kernel can be turned into a runc container breakout. There are a few public examples of such exploits such as Dirty COW and waitid().
Userspace processes access kernel functions through the use of syscalls. The potential impact of a kernel vulnerability can be mitigated by restricting the syscalls a container process is allowed to call. If a vulnerable kernel function cannot be accessed by the container process, it cannot be leveraged to break container isolation. seccomp is a feature of the Linux kernel that can be used to achieve precisely this. The default Docker seccomp profile is very permissive and blocks only about 40 of the available syscalls. While this allows for maximum application compatibility, it does very little when it comes to meaningfully decreasing the kernel attack surface.
When running containers in a production environment, it is a good idea to harden the AppArmor / SELinux and seccomp profiles. There are tools that claim to profile your application and generate such profiles for you that are worth investigating.
Nabla Containers
Nabla containers is a project from the IBM research team that uses a
rather novel approach for container isolation. Recall that for runc containers,
seccomp profiles can be used to restrict the number of syscalls a container
process can call. However, there is a limit to what you can restrict if you
still want to run a useful application inside the container. For example,
if you restrict the bind, send and recv syscalls, a container will be
unable to make any network connections, which makes the container pretty much
useless for running your typical web application.
The Linux kernel actually implements a lot of functionality behind a single
syscall. Using the bind, send and recv syscalls as examples, the kernel
will have to implement things like the TCP sliding window logic. The key idea
behind Nabla is to move all that logic into userspace so the only syscalls
the container will require are those that deal with the hardware. It does so
by linking what is known as Library OS into each container. The Library OS
functions implement in userspace the logic that usually occurs in the kernel.
The code for Library OS is taken from the Solo5 unikernel project.
With Nabla, you end up with a system that looks something like this:
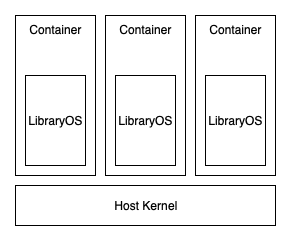
Nabla then applies a seccomp profile that only allows 7 syscalls through. They
are read, write, exit_group, clock_gettime, ppoll, pwrite64, and
pread64. With this approach, the kernel attack surface that can be accessed
by the container is thoroughly minimized.
The main drawback of the current implementation of Nabla is that the container image has to be specifically built for it. This is because the code needs to be compiled to use the Library OS functions instead of the standard libc that make use of syscalls.
Kata Containers
Kata Containers takes a very different approach to container isolation. Instead of relying on the standard namespaces, cgroups and capablities combination to isolate the container process, Kata runs each container in a stripped down QEMU virtual machine using the KVM hypervisor. Kata saves disk and memory space over a traditional VM through techniques like minimizing the rootfs and kernel or through the use of Kernel Samepage Merging (KSM) to deduplicate memory pages.
With Kata Containers, you end up with a system that looks something like this:
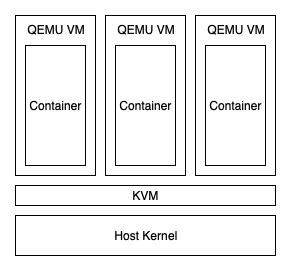
As Kata Containers are essentially KVM virtual machines, the isolation is as good as standard KVM, which is a pretty battle-tested hypervisor at this point.
The main drawback to this apparoch is performance. Even with efforts to reduce the disk and memory footprint of the QEMU VM being used, each Kata container will have more overhead than your typical libcontainer-based container runtime which is simply a Linux userspace process.
Firecracker
Firecracker is a recently open sourced container runtime from Amazon that uses a very similar approach to Kata containers. A very interesting point is that Amazon claims to use it to power their Lambda and Fargate offerings on AWS.
Like Kata Containers, Firecracker runs on the KVM hypervisor. Unlike Kata however, Firecracker does not make use of QEMU. Instead, Firecracker uses a custom Virtual Machine Monitor that apparently originated from Chrome OS' crosvm that provides the bare minimum functionality required to run the container.
According to the Firecracker's FAQ:
Firecracker provides a minimal required device model to the guest operating system while excluding non-essential functionality (there are only 4 emulated devices: virtio-net, virtio-block, serial console, and a 1-button keyboard controller used only to stop the microVM).
This improves performance and reduces the attack surface even further by removing a lot of the legacy devices that QEMU has. Remember, QEMU is designed to emulate arbitrary operating systems and architectures which comes with a fair bit of complexity.
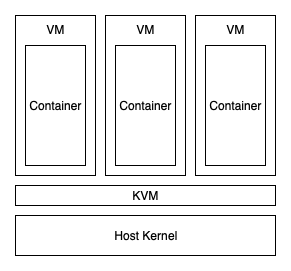
With Firecracker, you end up with a system that looks very similar to Kata
Containers:
gVisor
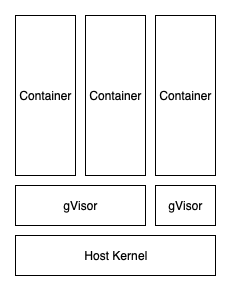
Finally, we have Google's gVisor project. gVisor works by emulating the Linux kernel in userspace. This means that any syscall that is called by the container process is proxied through gVisor which then does the neccessary work. gVisor stops the container process from directly communicating with the host kernel. Similar to Nabla, a lot of the kernel functionality is implemented in gVisor itself, which further minimizes the potential attack surface through the kernel.
With gVisor, you end up with a system that looks very similar to the following:
gVisor has a few interesting points:
- The gVisor kernel is written in Golang, which should remove the possibility of memory corruption vulnerabilities. However, implementation bugs are still possible.
- The gVisor process that talks to the host kernel is restricted with a seccomp profile that allows access to around 80 of about 300 possible syscalls. Like Nabla, this does reduce the potential attack surface through the kernel although it isn't as extreme as what Nabla does.
The main drawback to this approach is that syscall heavy application workloads will see a decrease in performance, as all syscalls are now proxied through the gVisor kernel.
Summary
In closing, we have looked at how the default Docker container runtime provides container isolation as well as how several promising alternative runtimes do things differently. This blog post only touch on each implementation very briefly. It is strongly recommended that interested readers take a look at the documentation for each runtime. As the container ecosystem changes incredibly fast, it will not surprise me if some of the details here become inaccurate after a few months. It will be interesting to see which runtime "wins" in the end.